「敦煌漢文佛教寫卷點校本工作手冊」:修訂間差異
imported>Putitz 小無編輯摘要 |
imported>Putitz 無編輯摘要 |
||
| 行 151: | 行 151: | ||
P-3436-0110 | P-3436-0110 | ||
|- | |- | ||
|省書例 Abbreviations | |||
|<choice><abbr><orig reg="卄卄"><g ref="#P2634-010-01"/></orig></abbr><expan>菩薩</expan></choice> | |<choice><abbr><orig reg="卄卄"><g ref="#P2634-010-01"/></orig></abbr><expan>菩薩</expan></choice> | ||
|[[圖片:省書1.jpg]] | |[[圖片:省書1.jpg]] | ||
|[[圖片:省書.jpg]] | |[[圖片:省書.jpg]] | ||
P-2634-0010 | P-2634-0010 | ||
|- | |||
|rowspan="4"|重文例 Repetition Mark | |||
|<choice><abbr>種〻</abbr><expan>種種</expan></choice> | |||
|[[圖片:重文2.jpg]] | |||
|[[圖片:重文1.jpg]] | |||
S-4064-0115 | |||
|- | |- | ||
|<choice><abbr>阿〻難〻</abbr><expan>阿難阿難</expan></choice> | |<choice><abbr>阿〻難〻</abbr><expan>阿難阿難</expan></choice> | ||
| 行 161: | 行 167: | ||
|[[圖片:重文例2.png]] | |[[圖片:重文例2.png]] | ||
P-3664-0511 | P-3664-0511 | ||
|- | |- | ||
|<choice><abbr>好〻如〻</abbr><expan>好好如如</expan></choice> | |<choice><abbr>好〻如〻</abbr><expan>好好如如</expan></choice> | ||
| 行 172: | 行 172: | ||
|[[圖片:S-4064-201.jpg]] | |[[圖片:S-4064-201.jpg]] | ||
S-4064-0201 | S-4064-0201 | ||
|- | |||
|<choice><abbr>努力〻〻</abbr><expan>努力努力</expan></choice> | |||
|[[圖片:省書12.jpg]] | |||
|[[圖片:重文例12.png]] | |||
R-0122-19r3 | |||
|- | |- | ||
|雙行夾注例 Notes inline or marginal in the Ms | |雙行夾注例 Notes inline or marginal in the Ms | ||
於 2017年9月6日 (三) 15:36 的最新修訂
敦煌漢文佛教寫卷點校本工作手冊
Critical Editions of Chinese Buddhist Dunhuang Manuscripts(Markup manual)
Date: 2016-10-7 Author: Chang, Po-Yung 張伯雍, Marcus Bingenheimer 馬德偉
本計畫為中華佛研所、馬德偉博士(Dr. Marcus Bingenheimer, Temple University)、太史文博士 (顧問)(Dr. Stephen F. Teiser, Princeton University)與大英圖書館國際敦煌專案(International Dunhuang Project, IDP)的合作專案。專案說明詳見計畫書。本計畫網站
寫卷數位化
數位化的寫卷標題範例:lengqieszj-S-4272.xml。S-4272 為敦煌文獻號碼。
所使用的標記規範為 TEI P5
寫卷結構與標記
- 以敦煌寫卷「件」為單位,即每一個檔案即為一件敦煌寫卷(如 S.4272)
| 行號標記例 | <lb xml:id="S-4272-0001"/> | ||
| 換紙或頁標記例 | <milestone unit="sheet" n="P-3664r-16"/> | 
|

P-3664-0332 |
| 空格標記例 Significant Spaces | <space type="honorific" unit="char" extent="1"/>(挪擡) | 
|

P-3664-0622 |
| <space type="punctuation" unit="char" extent="1"/>(段落) | 
|

S-4272-0008 | |
| <space type="bindingHole" unit="char" extent="1"/>(裝釘、穿線孔) | 
P-4646-01-03 | ||
| <space type="simpleSpace" unit="char" extent="1"/>(不明空格) | 
S-2054-0192 | ||
| <space type="verseSpacing" unit="char" extent="1"/>(斷偈句) | 
P-2634-0002 | ||
| 異寫字標記例 Character Variation | <orig reg="偽"><g ref="#S4272-005-11"/></orig>(專案新增) | S-4272-0005 | |
| <orig reg="障"><g ref="#A04441-003"/></orig>(教育部異體字字典) | S-4272-0013 | ||
| <orig reg="猶">由</orig>(通假字) | 
P-3434-0079 | ||
| 破損標記例 Damage | <damage unit="char" extent="1"/> | 
|

P-2460v-0001 |
| <damage>使鬼神</damage> | 
|

P-3436-0057 | |
| <unclear reason="damage">諸</unclear> | P-3436-0011 | ||
| 字跡不清標記例 Unclear | <unclear>經</unclear> | 
|

P-4745-0006 |
| 不造<unclear reason="illegible" unit="char" extent="2"/>不作 | 
P-3703-0006 | ||
| 取代標記例 Substitutions
(These are corrections found in the ms. Corrections by the project are marked with <corr>) |
<subst><del>无</del><add>有</add></subst> | S-4272-0005 | |
| <subst><del><unclear reason="illegible" unit="char" extent="1"/></del><add>心</add></subst> | S-4272-0021 | ||
| <subst><del resp="hand2"><orig reg="薩"><g ref="#A03580-001"/></orig></del><add resp="hand2" place="inline-right"><orig reg="提">禔</orig></add></subst> | 
P-3436-0037 | ||
| <subst><del resp="hand2">然見<orig reg="性"><g ref="#A01328-006"/></orig></del><add place="inline-right" resp="hand2" rendition="red">明</add></subst> | 
P-3777-0540 | ||
| 廢字例 Deletion Marks
(感謝 汪娟教授來函建議) |
者<del>者</del>非 | 
P-2460-0068v | |
| <del>清浄</del>解 | 
P-4646-08-04r | ||
| 插入/補充修改標記例 Additions | <add place="inline-right">性</add> | 
S-4272-0009 | |
| <add place="margin-bottom">軰</add> | (略不出) | 
P-3436-0056 | |
| 倒乙標記例 Reverse Mark | <orig reg="不出">出<pc resp="ms">㆑</pc>不</orig> | 
P-3436-0037 | |
| <lb xml:id="P-3436-0206"/><orig type="CJK" reg="坐"><pc resp="ms">㆑</pc>浄</orig> |  
P-3436-0206 | ||
| <orig reg="第二,魏朝"><orig reg="魏"><g ref="#A04688-002"/></orig>朝<add place="inline-right"><note resp="ms">向上</note></add><orig reg="第"><g ref="#P3664-356-17"/></orig>二</orig> | 
|

P-3436-0110 | |
| 省書例 Abbreviations | <choice><orig reg="卄卄"><g ref="#P2634-010-01"/></orig><expan>菩薩</expan></choice> | 
P-2634-0010 | |
| 重文例 Repetition Mark | <choice>種〻<expan>種種</expan></choice> | 
S-4064-0115 | |
| <choice>阿〻難〻<expan>阿難阿難</expan></choice> | 
P-3664-0511 | ||
| <choice>好〻如〻<expan>好好如如</expan></choice> | 
S-4064-0201 | ||
| <choice>努力〻〻<expan>努力努力</expan></choice> | R-0122-19r3 | ||
| 雙行夾注例 Notes inline or marginal in the Ms | <note resp="hand1" rendition="#inline-para">在舒州一名思空山</note> | 
P-3559-0567 | |
| 副標例 Subtitles | <hi rendition="#subtitle">并序</hi> | 
P-2634-0001 | |
| 專案訂正例 Corrections by project | <choice><sic>光濡</sic><corr>先儒</corr></choice><ptr target="#n7"/>不取
ptr (pointer) 是指關連到註解檔條目。 |

P-2634-0038r | |
| <orig reg="妄"><g ref="#A01309-003"/></orig>(音近而誤、假借) | 
P-2460-0105v | ||
| 偈文例 Verse lines | <lg><l><choice><orig><g ref="#A02941-036"/></orig><reg>稽</reg></choice>首<choice><orig><g ref="#A03222-001"/></orig><reg>善</reg></choice>知識<space type="verseSpacing" unit="char" extent="1"/><damage><choice><orig type="Ext-A">䏻</orig><reg>能</reg></choice>令<choice><orig><g ref="#P2634-002-08"/></orig><reg>護</reg></choice></damage>本心</l></lg> | 
|

P-2634-0002r |
| 衍字例 Extra characters | <surplus><add place="inline-right">元</add></surplus> | (略不出) | 
P-3664-0332 |
進階說明──文字迻錄原則
- 原則一、不論原文使用何種字體(楷書、行書、草書等),皆迻錄為楷書(楷化)。
- 原則二、Unicode 有提供字型者,按原字形迻錄。如:㘴,不改成為教育部標準字體(正字)「坐」。
- 原則三、因書寫造成的差異,以教育部異體字典收錄為準。如「工」教育部異體字典有「空」「
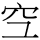 」的差別;但「差」「江」無此區別,故亦不區分。
」的差別;但「差」「江」無此區別,故亦不區分。 - 原則四、因文獻破損及字,若不妨礙判讀,則不加標記。雖有影響,但仍可識別(或藉其他本寫本可識別)者,以「達」字為例,標記如:<damaged>達</damaged>,在本計畫出版品作達。若不能辨識則作<unclear reason="illegible" unit="char" extent="1"/>,extent="1"指一個字,在本計畫出版品作▯。若文獻缺損,則作<damage unit="char" extent="3"/>,extent="3"指缺損部分在他本有3個字,在本計畫出版品作▯▯▯。If damaged but legible 達, if damaged and illegible ▯.
- 原則五、文獻為後世讀者所做之句讀,標記如<pc resp="hand2">.</pc>、<del resp="hand2"><pc resp="hand2">.</pc></del>。Old punctuation in the Ms: <pc resp="hand2">.</pc> <del resp="hand2"><pc resp="hand2">.</pc></del>
- 原則六、缺字編碼,教育部異體字典有錄者,從之;教育部異體字典未收,全字庫有錄者,從全字庫;未收於前二者,以敦煌文獻編號-行號-字序編碼,如 P3436-023-02。本計畫內之缺字若僅出現一次,且未被教育部異體字典、全字庫收錄者,編者斟酌以<reg>達</reg>(以「達」字為例)或其他缺字替代。若有特殊情形會加註解。<orig reg="詩"><g ref="#S-10484-01-09"/></orig>, only if there are more than one. Otherwise it is calligraphic -> <reg>
- 原則七、寫卷內容之更正(<corr>)標記,只會在孤本或所有寫本均錯誤的情形下,才會使用。若讀者可以藉由他本校出文字的脫漏、贅衍、錯誤,則不作更正。
Non-Unicode Variants - attested 萬國碼未收之異體字──已確認
|
Ex.1: S-4272-0002: 為除忘相<orig reg="修"><g ref="#A03335-004"/></orig>行六度 |
|
Non-Unicode Variants - unattested 萬國碼未收之異體字──未確認(專案新增)
|
Ex.1: S-4272-0022: 度眾生過去<orig reg="逢"><g ref="#S4272-022-14"/></orig>无量恒 |
|
"Unclear" Characters 模糊字
|
Ex.1: P-3703-0002:
無有邊<unclear>畔坐</unclear> |

|
Significant spaces 文中的空格
|
Ex.1: S-4272-0008 - S-4272-0010:
為中道<space unit="char" extent="2"/>苐三齊朝 人年十四遇達摩禪師 真登佛果<space unit="char" extent="1"/>楞伽経云 |

|
Character(s) added in the Ms. 插入字
|
Ex.1: S-4272-0009:
禪師俗<add place="inline-right">性</add>姖武窂人 |
|
| Character(s) Overwrite other Character(s): 覆蓋字
被覆蓋的字若不清楚則使用 |
Ex.1: S-4272-0021:
為是知眾生識<subst><del unit="char" extent="1"/><add>心</add></subst>自度 |
|
| Damaged but recognizable characters 破損字
<damage>與<unclear>近似,標記中直接使用正字。(範例中的字也可以識別為「忕」或「𢗗」,此處依另一版本。)<damage> is similar to <unclear> in that the text provided should be considered 通用字 as the variant can not be distinguished clearly. |
Ex.1: P-3703-0001 :
時<damage>狀</damage>𠰥 |

|
Unrecognizable characters due to accidental damage (tearing, breaking, smearing, blotting, smudging etc.) with later annotation 因意外而造成無法判讀(如撕裂、破損、磨滅、髒汙等),後來新增者
|
Ex.1: P-3703-0007:
In the header: <profileDesc> <creation> <listChange> <change xml:id="stage1">The manuscript is written, corrections were made by the scribe.寫卷抄錄時的修正</change><change xml:id="stage2">The verso is written. Ink seeps through blotting some characters.背面抄寫時的墨透背後所汙染者</change><change xml:id="stage3">A later hand clarifies characters that were blotted out.在汙處外再次訂正</change> </listChange> </creation> </profileDesc> 非<unclear>離</unclear>生<damage change="#stage2">法</damage><add change="#stage3" resp="hand2" place="inline-right">法</add><damage change="#stage2"><del change="#stage1" resp="hand1" unit="char" extent="1"/><add change="#stage1" place="inline-right" resp="hand1">有</add></damage><add change="#stage3" resp="hand2" place="inline-right">有</add>无生龍 一切圡木<damage change="#stage2">瓦</damage><add place="inline-right" change="#stage3">瓦</add>石
|

|
Reverse Mark 倒乙符號 (レ-点)
|
Ex.1: P-3436-0037:
亦出<add place="inline-right">㆑</add>不扵有 |
|
Repetition / Iteration Mark 叠字符號
|
 P-3664-0500 P-3664-0500
| |
Abbreviations 省書符號
|
Ex 1:P-3664-0511
<choice><abbr>阿〻<reg>難</reg>〻</abbr><expan>阿難阿難</expan></choice> |
|
| Ex 2:P-2634-0010
<choice>卄卄<expan>菩薩</expan></choice> |
| |
| Ex 3:S-2054-0325
<lb xml:id="S-2054-0325"/><choice><abbr>〻</abbr><expan>色</expan></choice> |

|

字型工具
- 最好安裝 Unicode Super-CJK Fonts v6.0
出版品表達原則
本計畫最終將所完成的標記文本出版成書,內容分為兩部分:A. 摹寫版,格式、用字俱儘量接近原始文獻;B. 對照點注版,用字均改現今標準字體,並加新式標點及注釋。
但為符合美觀及適讀性,訂出以下原則:
- 抄寫者的刪除、修改記號會保留在摹寫版中;若過程較複雜,則選擇最後一次所修改的樣貌。而對照點注版僅提供最終所要傳達的文字內容。In cases where a scribe corrects his own work we show the original and the correction in the diplomatic version, but give only final version, the one intended by the scribe, in the regularized output.
- 文獻中若出現二次或以上修改、標讀 (如 P.3664-580、619),仍將在摹寫版中出現。對照點注版原則上保留二次或以上修改記錄,並於必要時以注釋說明。In case where a second hand has made corrections to the text (e.g. P.3664, l.580, l.619), we show such interventions in the diplomatic edition, but give only the text of the original scribe in the regularized aligned version. We do not therefore present a genetic edition of the text.
- 判斷是否為原文或二次修改大致依前後文、筆跡、墨色等要素。At time it is unclear whether a change was done by the original scribe or a later redactor. Here we have to decide from the context. Do we see the same ink? Are there many other changes by a later redactor in that Ms.?
- 文獻上的標讀僅呈現於摹本中 (如 P.3664, 或 P.3777-506 等),標準字體標注本僅呈現本計畫的新式標點。Punctuation: Our own punctuation is added to the regularized version. In cases where a second hand has added punctuation this is shown in the diplomatic edition (e.g. P.3664, or P.3777, l.506 ff) but not in the regularized version.
- 若同時出現不同的讀號,則不加區分。In the diplomatic transcription the difference between the two hands is not expressed, we add a mark wherever either the red or the white hand made it.
XML 轉 InDesign 規則
說明 Abbreviations
Print1 = 摹寫版 Diplomatic Transcription
Print2 = 對照與點注版 Normalized Transcription
Damaged and Unclear Writing
1. 因文獻本身的破損而不能閱讀者 Characters are missing completely due to paper damage.
TEI: <damage unit="char" extent="2"/>
Print 1+2: 皆使用空心方格表示 In such cases both transcriptions use a place-holder (□). (轉換成<span>□□</span>)
2. 文字雖破損但不妨礙閱讀者 Character is partly damaged, but legible on its own.
TEI: <damage>字</damage>
Since the exact form of the glyph cannot be ascertained, in such cases both transcriptions give the regularized character.
Print 1: 以 reg 字元樣式表示 (轉換為<span rend="reg">字</span>)
Print 2: 以 normal 字元樣式表示 (轉換為<span>字</span>)
3. 文字雖破損但可藉其他文獻辨識者 Character is partly damaged and not legible on its own, but can be ascertained by other witnesses
TEI: <unclear reason="damage">字</unclear>
Print1: 以全形問號表示 Use the fullwidth question mark (?). (轉換成<span>?</span>)
Print2: 以 normal 字元樣式表示 Use the regularized transcription, given in <unclear>. (轉換為<span>字</span>)
4. 字跡不清需藉助其他文獻辨識者 Characters that are written illegibly/unclearly, but can be ascertained by using other witnesses
TEI: <unclear>字</unclear>
Print 1: 以全形問號表示 Use the fullwidth question mark (?). (轉換成<span>?</span>)
Print 2: 以 normal 字元樣式表示文字 Regularized (轉換為<span>字</span>)
5. 字跡不清亦無法藉助其他文獻辨識者 Characters that are written unclearly, and cannot be ascertained only by other witnesses (e.g. because there are no other witnesses)
TEI: <unclear unit="char" extent="1"/>
Print 1: 使用全形問號 Use the fullwidth question mark (?). (轉換成<span>?</span>)
Print 2: 使用空心方格表示 Use a place-holder (□). (轉換成<span>□</span>)
標點符號 Punctuation Characters/Marks <pc>
1. 本專案所加的標點 Our punctuation (No @resp on <pc>)
TEI: <pc>,</pc>
Print1: 隱藏,不呈現
Print2: 呈現
2. 寫本中的倒乙符號 Reverse mark ㆑in the Ms
TEI: <orig reg="念中">中<pc resp="ms">㆑</pc><orig type="Ext-D" reg="念">𫝹</orig></orig>
Print1: 比照寫本的排列方式,倒乙符號套用倒乙符號字元樣式 Show the reverse mark (轉換為<span rend="pc-reverse">㆑</span>) and the characters in the order and form as they appear in the Ms.
Print2: 以標準字體現示正確的排列 Display the characters in the correct order and in normalized form.
3. 寫卷中的句讀符號 Punctuation in the Ms
<pc resp="handPunct">.</pc>
Print 1: 以小紅點表示 Little red dots (轉換為<span rend="dot">.</span>)
Print 2: 不呈現
4. 寫卷中刪除句讀符號 "Deleted Punctuation" Punctuation in the Ms.
<del resp="hand"><pc resp="handPunct">.</pc></del>
Print 1: 以 ø 表示 Crossed out red dot. (轉換為<span rend="del-dot">ø</span>)
Print 2: 隱藏,不呈現
5. 寫卷中重文符號 "Iteration" Punctuation in the Ms.
如在文中,視同一般文字處理。如在行右側 <add place="inline-right">〻</add>
Print 1: 不加插入符號,直接顯示於右側 (轉換為<span rend="add-iteration">〻</span>)
Print 2: 顯示 <expan> 中的文字。
6. 寫卷中取代符號 "Substitute" Punctuation in the Ms.
<subst><del resp="hand2" rend="redDot">然見<orig reg="性"><g ref="#A01328-006"/></orig></del><add place="inline-right" resp="hand2" rend="red">明</add></subst>
Print 1: 被刪除字套用 del-redLine 字元樣式(因目前無法使用「點」,以「線」取代), 所新增文字套用 add-red 字元樣式。(轉換為<span rend="del-redLine">然見</span><img src="A01328-006.ai" type="g" width="12" height="12" crop="-40,-40,-40,-40" rend="del-g"/><span rend="del-red"> </span><span rend="add-red">\明/</span>)
Print 2: 僅顯示 <add> 中的文字。
逕用標準字體 Normalizations
所書寫的字形雖可辨識,但其結構不足以提供造字的情形下,以<reg>標記,並逕以標準字體表達。In cases where the character is relatively clearly visible, but the writing is not clear enough to identify what variant is used or allow to describe its shape in terms of radicals.
TEI: <reg>字</reg>
Print 1: 套用 reg 字元樣式 Use reg version. (轉換為<span rend="reg">字</span>)
Print 2: 以一般字元顯示 Use normalized version. (轉換為<span>字</span>)
(How does this differ from a non-Unicode character? No, it can't here.)
reg 在 choice 下
(I don't think there are any //choice/reg left.)
衍字 surplus
懷疑是卷中的雜寫,Print 1+2 俱不顯示。
分紙或分頁 milestone
<milestone unit="sheet" n="P-2460v-01"/>
Print 1: 以 ‖ 轉 90 度表示。 (轉換為<span rend="milestone">‖</span>)
Print 2: 不顯示。
orig
一般 orig
Print 1 如:<orig reg="憺"><g ref="#B01203-001"/></orig>,以缺字 <g ref="#B01203-001"/> 表達。
g: size: 12 top_crop: -40 bottom_crop: -40 left_crop: -40 right_crop: -40
g_inline: size: 5.8 top_crop: -55 bottom_crop: -35 left_crop: -30 right_crop: -30
g_add: size: 10 top_crop: -20 bottom_crop: -40 left_crop: -20 right_crop: -60
Print 2 以 reg="憺" 表達。(<span>憺</span>)
註解中的 orig (-notes.xml)
Print 1 無註解
Print 2 如:<orig reg="憺"><g ref="#B01203-001"/></orig>,以缺字 <g ref="#B01203-001"/> 表達,而非 reg="憺"。
g_note: size: 9 top_crop: -20 bottom_crop: -40 left_crop: -20 right_crop: -60
改正 Substitutions in the Mss and Corrections by our Project
抄寫者在寫卷中的修改 若原字清楚 Corrections made in the Ms, where the original characters are still legible
TEI: <subst><del><orig type="CJK" reg="無">旡</orig></del><add>有</add></subst>
Print 1: 刪除「旡」,「有」套用 normal 字元樣式。(<span rend="del">旡</span><span>有</span>,缺字請用<img src="P3294-001-20.ai" type="g" rend="normal" width="12" height="12" crop="-40,-40,-40,-40"/>形式)
Print 2: 寫「有」即可。(<span>有</span>)
範例出處: lengqieshiziji-S-4272.xml
抄寫者在寫卷中的修改 若原字不清楚 Corrections made in the Ms, where the original characters are no more legible
TEI: <subst><del><unclear reason="illegible" unit="char" extent="1"/></del><add><orig reg="第" type="CJK">苐</orig></add></subst>
Print 1: 刪除「□」,「苐」套用 normal 字元樣式,請注意是標記內的字。(<span rend="del">□</span><span>苐</span>)
Print 2: 寫「第」即可,請注意是 reg 的字。(<span>第</span>)
範例出處: guanxinlun-P-2657.xml
抄寫者插入的字
TEI: <subst><del><orig reg="薩"><g ref="#A03580-001"/></orig></del><add resp="hand2" place="inline-right"><orig reg="提">禔</orig></add></subst>
Print 1: 刪除「薩」,「禔」套用 subst-add 字元樣式,請注意是標記內的字。(<img src="A03580-001.ai" type="g" width="12" height="12" crop="-40,-40,-40,-40" rend="del-g"/><span rend="del"> </span><span rend="add">\禔/</span>)
Print 2: 寫「提」即可,請注意是 reg 的字。(<span>提</span>)
範例出處: guanxinlun-P-2657.xml
編輯者在對照與點注版的修改 Corrections made by us in the normalized text
TEI: <choice><sic>光濡</sic><corr>先儒</corr></choice>
Print 1: 作「光濡」。(<span>光濡</span>)
Print 2: 寫「光濡」,下加底線。(<nowiki>光濡)
範例出處: chuanfabaoji-P-2634.xml